
如何完成我的第一个数据项目?
这是我对我的项目“Who is bankrupt in China”的幕后记录。对我而言,这个项目的有趣之处在于,它通过真实世界的数据去窥视了中国的破产现象。
我记录了这个项目从无到有的过程,以及我从中遇到的问题和解决的思路。它与我一开始设想的项目成果相去甚远,但最后也踉跄着完成了。希望这篇文章可以纪录下在学习路上每一个踉跄的瞬间。
1.提出一个问题
虽然这是个数据分析的项目,但我认为最重要的一步是要先了解自己想问什么样的问题。打个比方,如果说数据分析是一个圆,那提出问题就该是数据分析的这个圆的原点。
我曾经有过很多不同的问题,比如破产公示到底是什么?这个制度到底是怎么新在哪里?多少钱可以算作破产?但这些问题都很容易回答。我随后把问题到具体到我认为既有趣,数据又可以回答的程度上,即“什么样的人在破产?”
于是,从该问题延伸出去,我便可以知道我需要了解哪些数据。这些数据应该可以帮我勾勒出破产者的具体形象,数据包括但不限于,年龄,性别,职业,收入和欠债数额等等。然后我会考虑这些数据是否能从网站上获得。到这里,我基本就确认了我会有哪些数据需要纳入到我的数据库存里,接下里就是收集数据。
2.收集数据
收集数据这步主要是技术类步骤。我用的是Web Scraper,只需要要基础的CSS 和 HTML的知识就可以使用。
我在这里主要遇到了3个问题。一是所有的破产者信息是不在一页上的,所以如果是直接用Web Scraper 提取相关数据就只能提取一页,就会需要每一页都重新抓取。

二是每一个破产者的详细信息,如破产声明是需要点进进入到链接里才能看到,在首页只能看到公示的名字和不完整的身份证号码。
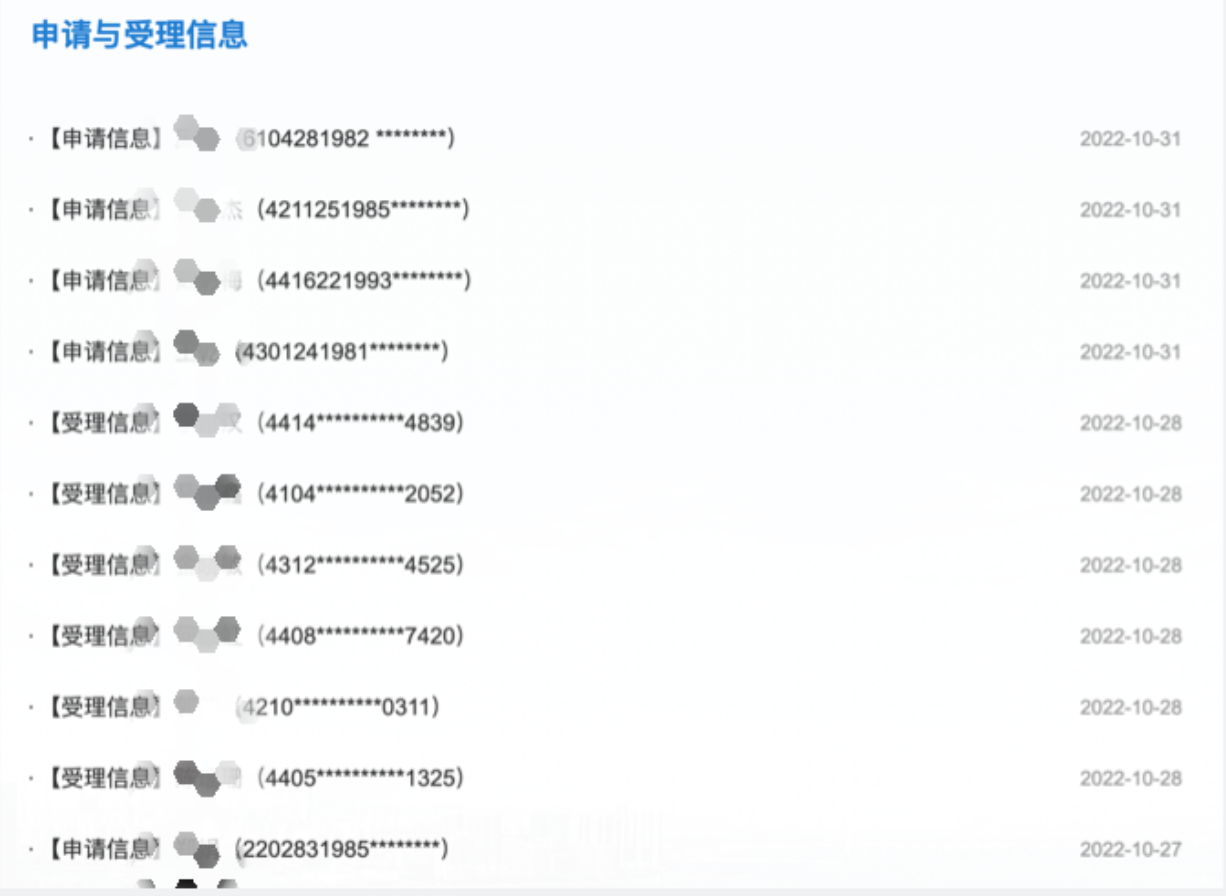
三是每一个破产者信息公示的CSS结构是不一样的。因为它是段落编码,如申报信息有的人是一段,有的人是两段。但Web Scraper只能识别同样的段落,即都是第一段或都是第二段。

我主要采取了三个方法来解决。一是设置了“自动翻页”,通过抓取时设置Web Scraper的链接翻页,让所有的页面的数据都可以一次性被收集完。二是设置“二级网页”的提取,因为所有的具体信息是需要点进链接里获得的。三是直接把申请者的信息整个div摘取下来。 这里具体的操作细节就不展开了,详细讲的话可能需要另一篇blog来讲解。
我最后一共获得了109条数据,包括以下数据类目:破产者姓名,破产者隐私保护后的身份证号,破产者申请时间和破产者声明。
3. 数据清洗
数据清洗是非常重要的衔接步骤。它直接影响了后面分析的可能。这一步是我学到最多知识的地方。常规的数据清洗包括去除重复和无效的数据。在去除重复信息和无效数据后,共有103条可用的数据。
如前文所述,在这次的项目里还有一个问题在于我想获得的信息是无法在数据抓取时便完成分类。所以我把数据分类也纳入到数据清洗里,因为它们的目的都是使得数据可以被进一步分析。
在这一步收集下来的103位破产者信息可以被分为两大类:一是有具体破产声明的破产信息公开。除了性别和出生年月外,这一类数据还包含了破产者对自己的破产经历的陈述,破产前的收入,破产后的资产清算和债务状况。第二类是破产申请公示,这一类数据只能看到破产者的不完整的身份证号。从不完整的身份证号中,我只能提取出性别的信息。第一类是本次项目的重点分析的数据,经过数据清洗后,共计34条。第二类有69条。
完成以上的大类分类后,我对34条详细数据进行了手动编码。这里的编码主要将破产者的详细信息分为以下五类:基本信息(年龄,性别),破产前收入,破产原因和债务数额。在这五类里,破产原因需要使用到内容分析进行二次编码。我这里主要参考了一些对个人破产研究的资料,归类出以下三类常见破产的原因:
1. 失业 (Loss a job)
2. 疾病(Medical expenses due to illness)
3. 消费 (Credit card debt)
但与中国语境相关的研究还指出,投资失败者是个人破产里的常见人群,因此我纳入了“投资”。同时,根据数据里还体现了被诈骗也是破产的一种原因。因此破产原因被分为了五大类风险:
- 失业 (Unemployment)
- 疾病 (Illlness)
- 消费 (Cousumption)
- 投资 (Investment)
- 诈骗 (Scam)
而这些风险在破产陈述中并不是单一原因,有的时候会涉及多重风险,如疾病和失业交织一起。
4.数据分析
数据分析是最重思考的步骤,也是用数据来回答问题的步骤。这一步充满了有趣的曲折的经历。
正如前面所说,我已经知道我需要的数据类别。然后在此基础上,我需要继续思考,这类数据能回答我的什么问题。举个例子,比如说我收集了关于性别的数据,那性别数据的结果可以告诉我什么呢?在这个思考的过程里,play data 成为了很重要的举动。
于是我先将男女性别分类,然后我发现男女之间的比例悬殊。我就会继续思考,那为什么会造成这个原因呢?于是我又回到了资料搜集里,看看性别差异在破产中的解释。然后我又试图将性别与申报的收入进行了对比,将性别与申报破产的原因做对比等等。
这一步中Excel的COUNTIFS函数非常有用。比如,通过将“性别”这个数据与不同的数据play在一起,我发现了很多有意思的话题。比如女性参与投资的比例很低,这有可能是之前研究中提到的,相比男性,女性对风险偏向持有保守的态度。然后我从不同s的数据交叉中,得出我觉得比较有意思的数据关系,将其放到我的分析里。
5. 数据可视化
数据可视化是我目前做得最吃力的一部分。我试过可视化软件如power BI 和 Tableau,但因为效果实在太差,最后在成品中都放弃了。转而回到了最开始的软件,用Excel来完成我的数据配图。
除了对软件的不熟悉外,我认为这里面还有原因是我尚未构建起可视化的思维,即我尚未清楚要用可视化表达什么。我这里借用了“procedural rhetoric”的概念去反思。“procedural rhetoric” 指的是在行为中去传递观点,从而实现说服的效果 (the practice of authoring arguments through processes)。从相反的视角而言,可视化是另一种实践,不同于文字表达,它有它自身的观点。因此需要先理解可视化的观点,从而才能做好可视化的表达。
这一点不足让我就算用Excel做图的时候也很痛苦。因为我不知道这些数据除了占比还能怎么处理成什么形式,或者它该用成什么样的图表。为什么这里不做成折线图?为什么这里需要做成柱状图?显然,就算是这么简单的图表,在这一环节我也花了很多时间去推倒重做。更不要说我本来是想做出可互动的数据图。
但也不是完全没有收获。在这一过程我学到的最重要的课程是,先思考我要表达什么信息,然后思考什么可视化会适合。比如我需要突出时间的对比,那折线图也许是个选择。但总而言之,在这一部分我没有太多可讲的,因为我的可视化做得实在一般。
6.数据反思
这一步是我追加的。在所有的分析内容和可视化做完后,我大概花了一天时间来阅读文章和资料来反思这个数据和这个项目本身的局限性。首先最明显一点是这个数据集都是深圳破产信息网上的资料,所以我是无法获得深圳市以外的破产数据的。因此它并不是中国破产者的数据,而是深圳破产者的数据。
其次是深圳本身作为中国的一线城市,大部分数据本身是不能代表真的中国的大多数水准。更不要说这份数据甚至不能代表深圳居民中的贫困群体或生活中并没有足够资产来抵抗多次风险的不幸的群体。
破产体现的是社会中的人生百态。但如果回顾这套法律的原则“帮助诚实但不幸的人”,我认为是不够准确的。毕竟从目前的数据而言,大部分时候更像是“帮助诚实但不幸的富裕的创业者”。这一点倒是和《脆弱的中产阶级》所言相似,“申请破产的人是社会的横截面,而破产是中产阶级的现象”。
“The people who file for bankruptcy are a cross-section of society, and bankruptcy is a middle-class phenomenon”
"The Fragile Middle Class: Americans in Debt"
阅读材料分享
以下是我阅读过的文章,它们为我的项目的分析提供了非常多样的思路。如果你对这一话题有兴趣,那你可能会也对我阅读过的材料感兴趣。
- "The Fragile Middle Class: American in Debt" – 讲了美国中产阶级的破产情况。虽然年代已久,但很有参考意义
- "Gender Gap in Personal Bankruptcy Risks: Empirical Evidence from Singapore" - 一篇研究破产风险的性别差异的学术文章。而且是新加坡语境的研究,更具有接近性
- "The Rhetoric of Video Games" – 让我思考了可视化的失败
- "Practice approaches and future trends in the personal bankruptcy system in China" – 很新的研究论文,讲了为什么需要个人破产制度以及当前司法实践的困境
- 《深圳未解之谜:工资一平均,个个是精英》 – 深圳人均收入统计思路
- 《人均负债4万多!》- 深圳人均负债统计。(小彩蛋:虽然我没有把负债数额的对比放到分析里,但目前已知的破产人平均负债已经远超过了深圳的居民负债数目。)
